Source
Flowlyze supporta due modalità di integrazione delle sorgenti: attiva e passiva. Entrambe consentono di acquisire, normalizzare e processare i dati in modo coerente all’interno della piattaforma.
Le modalità di ingresso sono due:
- Attiva (pull): Flowlyze preleva i dati dalle sorgenti a intervalli o su richiesta.
- Passiva (push): le sorgenti inviano eventi/messaggi a endpoint esposti da Flowlyze.
In entrambi i casi, i dati vengono acquisiti, normalizzati e instradati nelle stesse pipeline di trasformazione e validazione.
Modalità Attiva (pull)
A intervalli programmati o su richiesta (via API o azione manuale in UI), Flowlyze preleva i dati dalla sorgente e li carica nel database interno. Il trattamento successivo segue le regole definite nel flusso (pipeline, trasformazioni, validazioni).
Sorgenti tipiche
- Connettori API standard (REST/JSON).
- Database relazionali o NoSQL.
- Flat file (es. CSV) su storage locale o FTP/SFTP.
Esempi d’uso
- Ogni notte alle 00:00: importazione di un file CSV da uno spazio FTP.
- Ogni ora: lettura di una tabella da un database operativo.
Durante la fase di configurazione di una Source in Flowlyze è possibile definire, a livello generale, la ricorrenza dell’esecuzione tramite una cron expression.
Questa funzionalità consente di pianificare in modo flessibile e preciso la frequenza con cui la sorgente deve essere attivata (ad esempio ogni minuto, ogni ora, ogni giorno o in orari specifici).
Inoltre, è possibile specificare il tipo di integrazione utilizzata, selezionando tra le diverse modalità supportate da Flowlyze (ad esempio API REST, database, file system, webhook, eccetera), così da adattare il comportamento della Source alle esigenze del flusso di integrazione.
Per facilitare l’utilizzo anche in contesti globali, i riferimenti temporali della Cron Expression sono sempre in UTC (quindi non tengono conto della localizzazione dell’utilizzatore, né della time zone predefinita scelta per il tenant).
Nell’immagine seguente è mostrata la configurazione di base di una sorgente schedulata ogni minuto.
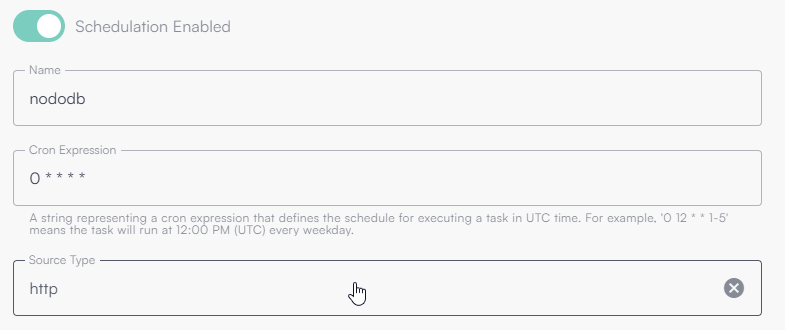
Questa configurazione indica che la Source di tipo Http (chiamata verso API) verrà eseguita ogni minuto di ogni ora, ogni giorno.
Cos’è una Cron Expression
Una cron expression è una stringa che definisce una pianificazione temporale ricorrente.
È composta da cinque o sei campi (a seconda del sistema), ognuno dei quali rappresenta un intervallo temporale:
| Campo | Descrizione | Valori possibili |
|---|---|---|
| 1 | Minuti | 0–59 |
| 2 | Ore | 0–23 |
| 3 | Giorno del mese | 1–31 |
| 4 | Mese | 1–12 o nomi (JAN–DEC) |
| 5 | Giorno della settimana | 0–6 o nomi (SUN–SAT) |
Esempi di cron expression
| Cron expression | Significato |
|---|---|
* * * * * | Ogni minuto |
0 * * * * | Ogni ora, al minuto 0 |
0 0 * * * | Ogni giorno a mezzanotte |
0 9 * * 1-5 | Ogni giorno lavorativo alle 09:00 |
*/15 * * * * | Ogni 15 minuti |
0 0 1 * * | Il primo giorno di ogni mese a mezzanotte |
Gestione dati incrementali
Flowlyze mette a disposizione un sistema di memoria integrato che consente di implementare letture incrementali dalle sorgenti dati, ottimizzando così le performance dei flussi e riducendo la quantità di dati processati a ogni esecuzione.
Si identifica un campo discriminante (timestamp/ordinamento). Ad ogni run viene memorizzato il valore massimo processato; al successivo run si leggono solo i record successivi. Questo riduce in modo significativo il carico sulle sorgenti e sui flussi.
Il meccanismo si basa sull’identificazione di un campo discriminante nella sorgente (ad esempio una colonna di un database o un campo presente nel payload di una chiamata HTTP) che rappresenta la sequenzialità o l’ordine temporale dei dati.
Durante ogni esecuzione, Flowlyze memorizza il valore massimo (o altro criterio di aggregazione) ottenuto per quel campo all’interno del set di dati processati.
Nell’esecuzione successiva, tale valore viene utilizzato come punto di riferimento per richiedere solo i nuovi record o quelli modificati dopo l’ultimo aggiornamento.
Esempio di comportamento
Supponiamo che la sorgente contenga un campo last_update che rappresenta la data di ultima modifica di ogni record.
Alla prima esecuzione, Flowlyze elabora tutti i dati disponibili e registra il valore frutto di un’operazione di aggregazione (generalmente il valore massimo di last_update trovato.
All’esecuzione successiva, la piattaforma userà tale valore per interrogare la sorgente, richiedendo solo i dati con last_update successivo a quello memorizzato.
In questo modo, il sistema evita la rilettura di dati già processati, garantendo efficienza, coerenza e scalabilità del flusso.
Parametri di configurazione
La configurazione del meccanismo incrementale è completamente personalizzabile e consente di definire i seguenti campi:
| Campo | Descrizione |
|---|---|
| Nome variabile | Identifica la variabile associata al campo incrementale. Può essere richiamata all’interno delle configurazioni tramite la sintassi `{{nome_variabile}}`. |
| Message JSON Path | Espressione JSONPath che individua, all’interno del messaggio o del payload, il campo discriminante da utilizzare per la lettura incrementale. |
| Aggregator | Criterio di aggregazione applicato al campo per determinare il valore da memorizzare (ad esempio max, min, ecc.). Nella maggior parte dei casi viene utilizzato max. |
| Current value | Valore attuale memorizzato per il campo incrementale. Può essere impostato o modificato manualmente per forzare una ripartenza da un punto specifico. |
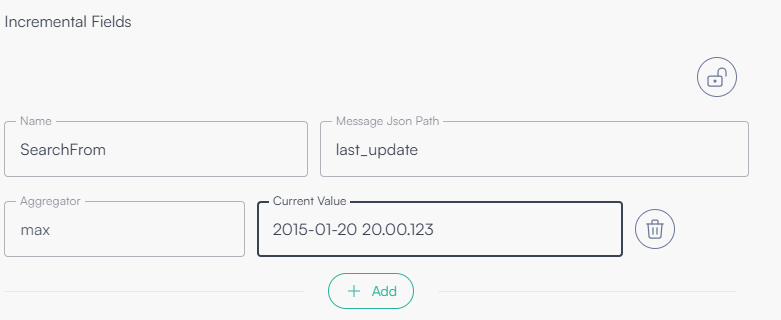
Esempio di configurazione
Nell’immagine seguente è riportato un esempio di configurazione che utilizza il campo last_update come discriminante per la lettura incrementale.
Modalità Passiva (push)
Flowlyze espone un endpoint al quale i sistemi esterni inviano i dati (singoli record o batch). È il modello ideale per eventi in tempo quasi reale.
Proteggi l’endpoint con API Key e limita il path per tenant. Verifica i limiti di rate e firma dei messaggi quando disponibili.
Esempio d’uso
- Un e-commerce invia una variazione ordine tramite webhook verso l’endpoint REST di Flowlyze.
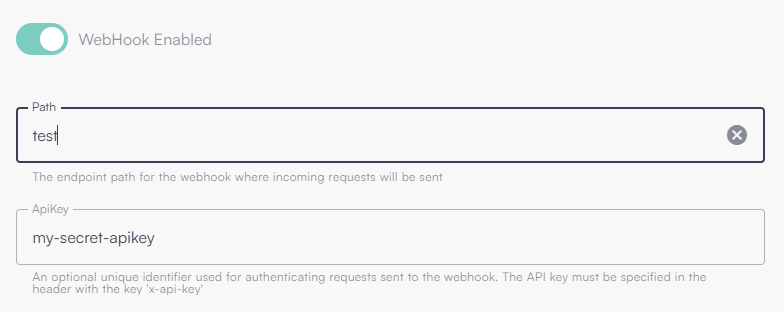
Di seguito un’immagine che rappresenta l’attivazione di un endpoint, con path “test” e apikey “my-secret-apikey”
Modalità combinate
Le due modalità possono coesistere. La stessa sorgente può:
- inviare eventi in push (webhook) per gli aggiornamenti,
- essere sincronizzata in pull a cadenza regolare per garantire allineamento e consistenza.
Processo unificato
Indipendentemente dalla modalità di ingresso (attiva o passiva), tutti i dati:
- Vengono acquisiti nel database interno di Flowlyze.
- Sono aggregati e normalizzati (schema, formati, codifiche).
- Seguono lo stesso flusso di trasformazione, arricchimento, validazione e consegna verso le destinazioni previste.
Questo approccio assicura uniformità operativa, tracciabilità e scalabilità del trattamento dati.
Http Ingestion (Push)
Endpoint V2
L’endpoint V2 consente di definire il modello dati lato client, svincolando il chiamante dal dover rispettare uno schema preconfigurato. In pratica, chiunque disponga di URL (Uniform Resource Locator) e API Key può scegliere liberamente il formato del payload, entro le opzioni supportate.
Il parser viene scelto automaticamente in base al MIME type dichiarato nell’header `Content-Type`:
- JSON →
`application/json` - XML →
`application/xml,text/xml` - Form →
`application/x-www-form-urlencoded,multipart/form-data`
Invio in formato JSON
Nel caso in cui sia indicato il parametro x-fl-selector viene utilizzato il sotto oggetto puntato Selettore opzionale x-fl-selector
Se è presente il query parameter HTTP x-fl-selector, l’endpoint applica l’espressione JSONPath indicata per individuare il sotto-oggetto (o l’elenco) da processare.
Se l’header non è presente, viene utilizzato l’oggetto alla root del body JSON.L’endpoint identifica automaticamente se il payload rappresenta un singolo messaggio (oggetto) oppure un insieme di messaggi (array). Le espressioni JSONPath possono selezionare elementi annidati e liste.
Esempi (JSON)
| # | Input (schematico) | Content-Type | x-fl-selector | Interpretazione |
|---|---|---|---|---|
| 1 | `[{}, {}, {}]` | application/json | (omesso) | L’intero array è un batch: 3 messaggi. |
| 2 | `{ "data": [ {}, {}, {} ] }` | application/json | data | Seleziona data: batch di 3 messaggi. |
| 3 | `[ { "children": [ {}, {}, {} ] }, { "children": [ {}, {}, {} ] }, { "children": [ {}, {}, {} ] } ]` | application/json | $.*.children[*] | Seleziona e appiattisce tutti i children: 9 messaggi. |
Nota: gli esempi sono volutamente compatti e privi di campi applicativi; in produzione i singoli {} rappresentano record/oggetti completi.
Se il parsing del payload fallisce, Flowlyze crea comunque un messaggio di fallback che contiene un campo content con il contenuto originale ricevuto. Questo garantisce tracciabilità e possibilità di ritentare l’elaborazione a valle.
Invio batchId
L’endpoint consente l’invio di un Batch ID per richiesta. I parametri possono essere forniti tramite header oppure tramite query string.
Parametri supportati
| Nome parametro | Tipo | Obbligatorio | Descrizione |
|---|---|---|---|
batchId | string | Sì | Identificativo univoco del batch (ObjectId). È consentito un solo valore per richiesta. |
processableBatch | boolean | No | Indica se il batch deve essere processato. |
Regole di elaborazione
- Se
processableBatch = true→ lo stato del batch viene impostato aPROCESSING - Se
processableBatch = falseo non fornito → lo stato del batch viene impostato aDATA_LOADING
Endpoint V1
L’endpoint V1, in fase di dismissione, si basa su una struttura dati definita a priori. Ciò significa che il flusso deve essere configurato anticipatamente per interpretare correttamente il payload in ingresso.
All’interno del flusso è necessario specificare:
L’endpoint V1 è deprecato e in dismissione. Si consiglia la migrazione verso V2 per flessibilità e robustezza.
- Consider as single object: se l’endpoint riceve un singolo oggetto
- path: percorso univoco della url (ultima parte del percorso
https://in.flowlyze.io/api/wh/{tenant_id}/{path}) - apikey: chiave univoca da passare in query string oppure in header sotto con nome di parametro x-api-key
Esempio: https://in.flowlyze.io/api/wh/flowlyze-demo/test for tenant flowlyze-demo and path test.
Parametri richiesti nel flusso
Consider as single object
Indica se l’endpoint riceve un singolo oggetto JSON per richiesta (true) oppure un insieme di oggetti (array).
- true → il payload è un singolo record.
- false → il payload è una lista di record.
Path
Percorso univoco in coda alla URL che identifica l’istanza del webhook all’interno del tenant.
Esempio: in /flowlyze-demo/test, il path è test.
API Key
Chiave univoca da fornire per l’autenticazione:
- In query string:
?x-api-key=<CHIAVE> - Oppure via HTTP header:
x-api-key: <CHIAVE>
Esempio di URL
Per il tenant flowlyze-demo e path test: https://in.flowlyze.io/api/wh/flowlyze-demo/test
Autenticazione con query string: https://in.flowlyze.io/api/wh/flowlyze-demo/prova?x-api-key=<CHIAVE>
Autenticazione con HTTP header (consigliato), esempio curl:
curl -X POST \
https://in.flowlyze.io/api/wh/flowlyze-demo/prova \
-H "x-api-key: <CHIAVE>" \
-H "Content-Type: application/json" \
-d '{ "example": "value" }'
Stato di vita e migrazione
L’endpoint V1 è in dismissione. Per una maggiore flessibilità di schema (selettori, formati, autodiscovery del batch), si raccomanda la migrazione a Endpoint V2, che permette la definizione del modello dati lato client e supporta selezione tramite JSONPath.
Connettori
📄️ HTTP (pull)
Una Source di tipo HTTP in Flowlyze è progettata per leggere e acquisire dati da endpoint remoti accessibili via protocollo HTTP o HTTPS, tipicamente esposti da servizi web, API REST o microservizi.
📄️ GraphQL
Una Source di tipo GraphQL in Flowlyze è un job di ingresso schedulato che, in base alla pianificazione del flusso (es. cron), chiama un endpoint GraphQL, invia la richiesta (query o mutation) e mette in coda il payload di risposta per l'elaborazione. Estende il comportamento delle sorgenti HTTP e utilizza le impostazioni GraphQL del flusso per costruire la richiesta, inviarla e interpretare la risposta.
📄️ RDBMS (SQL)
La Source di tipo RDBMS (SQL) in Flowlyze consente di connettersi ai principali database relazionali per estrarre dati tramite una query SQL personalizzabile.
📄️ Flat file
La Source di tipo Flat File in Flowlyze consente di leggere e interpretare file strutturati in diversi formati (CSV, posizionale, XML, JSON) provenienti da una varietà di canali di acquisizione (FTP, HTTP, S3, Azure Blob Storage).
📄️ MongoDB
La Source di tipo MongoDB in Flowlyze consente di leggere dati da MongoDB tramite connection string e interrogazioni configurabili.