Source
Flowlyze supports two ways to ingest data from sources: active (pull) and passive (push). Both let you acquire, normalize, and process data consistently across the platform.
There are two ingestion modes:
- Active (pull): Flowlyze fetches data from sources on a schedule or on demand.
- Passive (push): sources send events/messages to endpoints exposed by Flowlyze.
In both cases, data is acquired, normalized, and sent through the same transformation and validation pipelines.
Active Mode (pull)
On a schedule or on demand (via API or manual action in the UI), Flowlyze pulls data from the source and loads it into the internal database. Subsequent processing follows the rules defined in the flow (pipelines, transformations, validations).
Typical sources
- Standard API connectors (REST/JSON)
- Relational/NoSQL databases
- Flat files (e.g., CSV) from local storage or FTP/SFTP
Use cases
- Every night at 00:00: import a CSV file from an FTP location
- Every hour: read a table from an operational database
When configuring a Source, you can define a global recurrence using a cron expression.
This lets you precisely schedule how often the source should run (every minute, hourly, daily, or at specific times).
You can also specify the integration type used by Flowlyze (e.g., REST API, database, file system, webhook) so that the Source behavior fits the flow requirements.
All Cron Expression times are in UTC (independent of user locale or tenant default time zone).
The following image shows a source scheduled every minute.
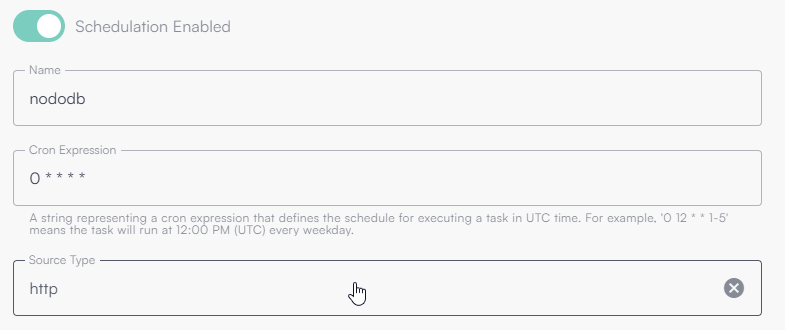
This configuration means an HTTP Source (outbound API call) will run every minute of every hour, every day.
What is a Cron Expression
A cron expression defines a recurring schedule.
It consists of five or six fields (depending on the system), each representing a time component:
| Field | Description | Allowed values |
|---|---|---|
| 1 | Minutes | 0–59 |
| 2 | Hours | 0–23 |
| 3 | Day of month | 1–31 |
| 4 | Month | 1–12 or names (JAN–DEC) |
| 5 | Day of week | 0–6 or names (SUN–SAT) |
Cron expression examples
| Cron expression | Meaning |
|---|---|
* * * * * | Every minute |
0 * * * * | Hourly at minute 0 |
0 0 * * * | Every day at midnight |
0 9 * * 1-5 | Weekdays at 09:00 |
*/15 * * * * | Every 15 minutes |
0 0 1 * * | First day of the month at midnight |
Incremental reads
Flowlyze provides a built-in memory that enables incremental reads, improving flow performance and reducing the amount of processed data.
Choose a discriminating field (timestamp/order). After each run, Flowlyze stores the max processed value; at the next run it only reads records after that value. This significantly reduces load on sources and flows.
The mechanism is based on identifying a discriminating field in the source (e.g., a database column or an HTTP payload field) that represents sequence or time order.
On each execution, Flowlyze stores the maximum (or another aggregate) value observed for that field.
On the next execution, that value is used as a reference to request only new or updated records.
Example behavior
Assume the source has a last_update field.
During the first run, Flowlyze processes all available data and stores the aggregate value (typically the maximum last_update).
On the next run, Flowlyze queries only records with last_update later than the stored value.
This avoids re-reading already processed data, ensuring efficiency, consistency, and scalability.
Configuration parameters
| Field | Description |
|---|---|
| Variable name | Identifies the variable bound to the incremental field. Can be referenced using `{{variable_name}}`. |
| Message JSON Path | JSONPath expression pointing to the discriminating field to use for incremental reading. |
| Aggregator | Aggregate used to select the value to store (e.g., max, min, etc.). Most commonly max. |
| Current value | The current stored value; can be set/overridden manually to restart from a specific point. |
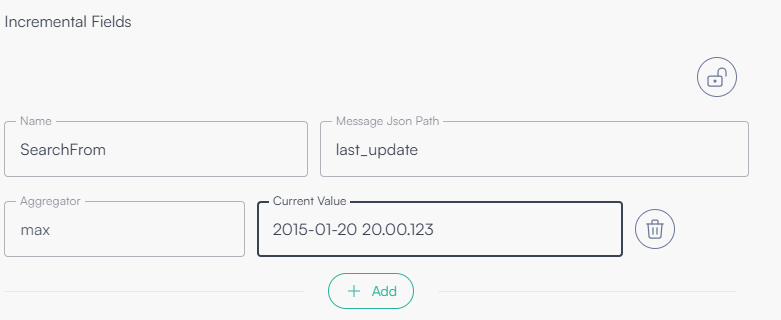
Configuration example
The following image shows a configuration that uses last_update as the incremental field.
Passive Mode (push)
Flowlyze exposes an endpoint that external systems can call to send data (single records or batches). This is ideal for near real-time event ingestion.
Protect the endpoint with an API Key and scope its path per tenant. Consider rate limits and message signatures when available.
Use case
- An e-commerce sends an order update via webhook to the Flowlyze REST endpoint
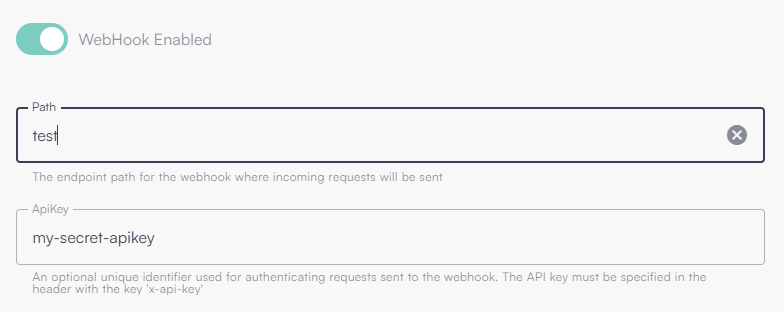
Below is an example of enabling an endpoint with path “test” and API key “my-secret-apikey”.
Combined modes
Both modes can coexist. The same source can:
- send updates in push (webhook), and
- be synchronized in pull periodically to ensure alignment and consistency.
Unified process
Regardless of the ingress mode (active or passive), all data:
- Is acquired into Flowlyze’s internal database
- Is aggregated and normalized (schema, formats, encodings)
- Follows the same flow of transformation, enrichment, validation, and delivery to destinations
This ensures operational uniformity, traceability, and scalability.
Http Ingestion (Push)
Endpoint V2
The V2 endpoint allows you to define the data model on the client side, removing the need to conform to a preconfigured schema. Anyone with the URL and API Key can pick the payload format among supported options.
The parser is automatically chosen based on the Content-Type header:
- JSON →
application/json - XML →
application/xml,text/xml - Form →
application/x-www-form-urlencoded,multipart/form-data
JSON payload
If the x-fl-selector query parameter is provided, the endpoint uses the pointed sub-object
If the HTTP query parameter x-fl-selector is present, the endpoint applies the given JSONPath expression to select the sub-object (or list) to process.
If the header is missing, the root object of the JSON body is used. The endpoint automatically detects whether the payload is a single message (object) or a batch (array). JSONPath expressions can select nested elements and lists.
Examples (JSON)
| # | Input (schematic) | Content-Type | x-fl-selector | Interpretation |
|---|---|---|---|---|
| 1 | `[{}, {}, {}]` | application/json | (omitted) | The whole array is a batch: 3 messages. |
| 2 | `{ "data": [ {}, {}, {} ] }` | application/json | data | Selects data: batch of 3 messages. |
| 3 | `[ { "children": [ {}, {}, {} ] }, { "children": [ {}, {}, {} ] }, { "children": [ {}, {}, {} ] } ]` | application/json | $.*.children[*] | Selects and flattens all children: 9 messages. |
Note: examples are compact and omit business fields; each {} represents a complete record/object in production.
If payload parsing fails, Flowlyze still creates a fallback message containing a content field with the original payload for traceability and potential downstream retries.
BatchId submission
The endpoint allows sending one Batch ID per request. Parameters can be provided via HTTP headers or via query string.
Supported parameters
| Parameter name | Type | Required | Description |
|---|---|---|---|
batchId | string | Yes | Unique batch identifier (ObjectId). Only one value per request is allowed. |
processableBatch | boolean | No | Indicates whether the batch should be processed. |
Endpoint V1
The V1 endpoint (being phased out) relies on a predefined schema. The flow must be configured in advance to correctly interpret the incoming payload.
Within the flow you must specify:
V1 is deprecated and being retired. Migrate to V2 for flexibility and robustness.
- Consider as single object: whether the endpoint receives a single object
- path: unique URL tail (last part of
https://in.flowlyze.io/api/wh/{tenant_id}/{path}) - apikey: key passed either as query string or header
x-api-key
Example: https://in.flowlyze.io/api/wh/flowlyze-demo/test for tenant flowlyze-demo and path test.
Required parameters in the flow
Consider as single object
Whether the endpoint receives a single JSON object per request (true) or a list of objects (array).
- true → payload is a single record
- false → payload is a list of records
Path
Unique tail at the end of the URL identifying the webhook instance within the tenant.
Example: in /flowlyze-demo/test, the path is test.
API Key
Unique key required for authentication:
- Query string:
?x-api-key=<KEY> - HTTP header:
x-api-key: <KEY>
URL examples
For tenant flowlyze-demo and path test: https://in.flowlyze.io/api/wh/flowlyze-demo/test
Authentication via query string: https://in.flowlyze.io/api/wh/flowlyze-demo/prova?x-api-key=<KEY>
Authentication via HTTP header (recommended), curl example:
curl -X POST \
https://in.flowlyze.io/api/wh/flowlyze-demo/prova \
-H "x-api-key: <KEY>" \
-H "Content-Type: application/json" \
-d '{ "example": "value" }'
Lifecycle and migration
V1 is being phased out. For schema flexibility (selectors, formats, batch autodiscovery), migrate to V2, which lets clients define the data model and supports JSONPath selection.
Connectors
📄️ HTTP (pull)
An HTTP Source in Flowlyze reads and acquires data from remote endpoints over HTTP/HTTPS, typically exposed by web services, REST APIs, or microservices.
📄️ GraphQL
A GraphQL Source in Flowlyze is a scheduled inbound job that, based on the flow schedule (e.g. cron), calls a GraphQL endpoint, sends a request (query or mutation), and enqueues the response payload for processing.
📄️ RDBMS (SQL)
An RDBMS (SQL) Source connects to relational databases and extracts data using a custom SQL query.
📄️ Flat file
A Flat File Source reads and parses structured files in multiple formats (CSV, positional, XML, JSON) from various acquisition channels (FTP, HTTP, S3, Azure Blob Storage).
📄️ MongoDB
A MongoDB Source in Flowlyze reads data from MongoDB using a connection string and configurable queries.