Source
Flowlyze supporta due modalità di integrazione delle sorgenti: attiva e passiva. Entrambe consentono di acquisire, normalizzare e processare i dati in modo coerente all’interno della piattaforma.
Le modalità di ingresso sono due:
- Attiva (pull): Flowlyze preleva i dati dalle sorgenti a intervalli o su richiesta.
- Passiva (push): le sorgenti inviano eventi/messaggi a endpoint esposti da Flowlyze.
In entrambi i casi, i dati vengono acquisiti, normalizzati e instradati nelle stesse pipeline di trasformazione e validazione.
Modalità Attiva (pull)
A intervalli programmati o su richiesta (via API o azione manuale in UI), Flowlyze preleva i dati dalla sorgente e li carica nel database interno. Il trattamento successivo segue le regole definite nel flusso (pipeline, trasformazioni, validazioni).
Sorgenti tipiche
- Connettori API standard (REST/JSON).
- Database relazionali o NoSQL.
- Flat file (es. CSV) su storage locale o FTP/SFTP.
Esempi d’uso
- Ogni notte alle 00:00: importazione di un file CSV da uno spazio FTP.
- Ogni ora: lettura di una tabella da un database operativo.
Durante la fase di configurazione di una Source in Flowlyze è possibile definire, a livello generale, la ricorrenza dell’esecuzione tramite una cron expression.
Questa funzionalità consente di pianificare in modo flessibile e preciso la frequenza con cui la sorgente deve essere attivata (ad esempio ogni minuto, ogni ora, ogni giorno o in orari specifici).
Inoltre, è possibile specificare il tipo di integrazione utilizzata, selezionando tra le diverse modalità supportate da Flowlyze (ad esempio API REST, database, file system, webhook, eccetera), così da adattare il comportamento della Source alle esigenze del flusso di integrazione.
Per facilitare l’utilizzo anche in contesti globali, i riferimenti temporali della Cron Expression sono sempre in UTC (quindi non tengono conto della localizzazione dell’utilizzatore, né della time zone predefinita scelta per il tenant).
Nell’immagine seguente è mostrata la configurazione di base di una sorgente schedulata ogni minuto.
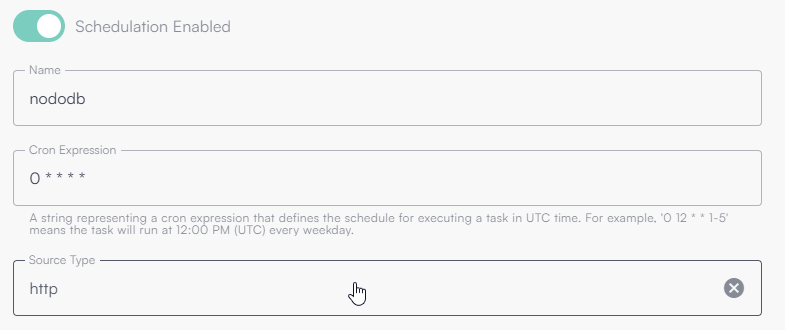
Questa configurazione indica che la Source di tipo Http (chiamata verso API) verrà eseguita ogni minuto di ogni ora, ogni giorno.
Cos’è una Cron Expression
Una cron expression è una stringa che definisce una pianificazione temporale ricorrente.
È composta da cinque o sei campi (a seconda del sistema), ognuno dei quali rappresenta un intervallo temporale:
| Campo | Descrizione | Valori possibili |
|---|---|---|
| 1 | Minuti | 0–59 |
| 2 | Ore | 0–23 |
| 3 | Giorno del mese | 1–31 |
| 4 | Mese | 1–12 o nomi (JAN–DEC) |
| 5 | Giorno della settimana | 0–6 o nomi (SUN–SAT) |
Esempi di cron expression
| Cron expression | Significato |
|---|---|
* * * * * | Ogni minuto |
0 * * * * | Ogni ora, al minuto 0 |
0 0 * * * | Ogni giorno a mezzanotte |
0 9 * * 1-5 | Ogni giorno lavorativo alle 09:00 |
*/15 * * * * | Ogni 15 minuti |
0 0 1 * * | Il primo giorno di ogni mese a mezzanotte |
Gestione dati incrementali
Flowlyze mette a disposizione un sistema di memoria integrato che consente di implementare letture incrementali dalle sorgenti dati, ottimizzando così le performance dei flussi e riducendo la quantità di dati processati a ogni esecuzione.
Si identifica un campo discriminante (timestamp/ordinamento). Ad ogni run viene memorizzato il valore massimo processato; al successivo run si leggono solo i record successivi. Questo riduce in modo significativo il carico sulle sorgenti e sui flussi.
Il meccanismo si basa sull’identificazione di un campo discriminante nella sorgente (ad esempio una colonna di un database o un campo presente nel payload di una chiamata HTTP) che rappresenta la sequenzialità o l’ordine temporale dei dati.
Durante ogni esecuzione, Flowlyze memorizza il valore massimo (o altro criterio di aggregazione) ottenuto per quel campo all’interno del set di dati processati.
Nell’esecuzione successiva, tale valore viene utilizzato come punto di riferimento per richiedere solo i nuovi record o quelli modificati dopo l’ultimo aggiornamento.
Esempio di comportamento
Supponiamo che la sorgente contenga un campo last_update che rappresenta la data di ultima modifica di ogni record.
Alla prima esecuzione, Flowlyze elabora tutti i dati disponibili e registra il valore frutto di un’operazione di aggregazione (generalmente il valore massimo di last_update trovato.
All’esecuzione successiva, la piattaforma userà tale valore per interrogare la sorgente, richiedendo solo i dati con last_update successivo a quello memorizzato.
In questo modo, il sistema evita la rilettura di dati già processati, garantendo efficienza, coerenza e scalabilità del flusso.
Parametri di configurazione
La configurazione del meccanismo incrementale è completamente personalizzabile e consente di definire i seguenti campi:
| Campo | Descrizione |
|---|---|
| Nome variabile | Identifica la variabile associata al campo incrementale. Può essere richiamata all’interno delle configurazioni tramite la sintassi `{{nome_variabile}}`. |
| Message JSON Path | Espressione JSONPath che individua, all’interno del messaggio o del payload, il campo discriminante da utilizzare per la lettura incrementale. |
| Aggregator | Criterio di aggregazione applicato al campo per determinare il valore da memorizzare (ad esempio max, min, ecc.). Nella maggior parte dei casi viene utilizzato max. |
| Current value | Valore attuale memorizzato per il campo incrementale. Può essere impostato o modificato manualmente per forzare una ripartenza da un punto specifico. |
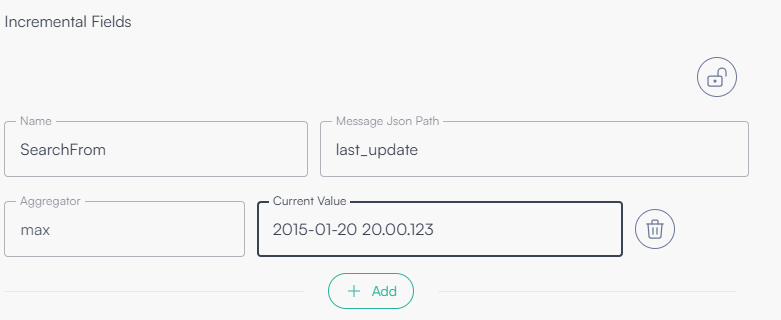
Esempio di configurazione
Nell’immagine seguente è riportato un esempio di configurazione che utilizza il campo last_update come discriminante per la lettura incrementale.
Modalità Passiva (push)
Flowlyze espone un endpoint al quale i sistemi esterni inviano i dati (singoli record o batch). È il modello ideale per eventi in tempo quasi reale.
Proteggi l’endpoint con API Key e limita il path per tenant. Verifica i limiti di rate e firma dei messaggi quando disponibili.
Esempio d’uso
- Un e-commerce invia una variazione ordine tramite webhook verso l’endpoint REST di Flowlyze.
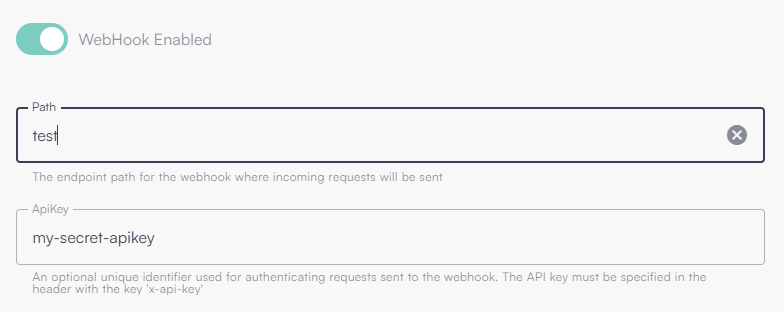
Di seguito un’immagine che rappresenta l’attivazione di un endpoint, con path “test” e apikey “my-secret-apikey”
Modalità combinate
Le due modalità possono coesistere. La stessa sorgente può:
- inviare eventi in push (webhook) per gli aggiornamenti,
- essere sincronizzata in pull a cadenza regolare per garantire allineamento e consistenza.
Processo unificato
Indipendentemente dalla modalità di ingresso (attiva o passiva), tutti i dati:
- Vengono acquisiti nel database interno di Flowlyze.
- Sono aggregati e normalizzati (schema, formati, codifiche).
- Seguono lo stesso flusso di trasformazione, arricchimento, validazione e consegna verso le destinazioni previste.
Questo approccio assicura uniformità operativa, tracciabilità e scalabilità del trattamento dati.
Http Ingestion (Push)
Endpoint V2
L’endpoint V2 consente di definire il modello dati lato client, svincolando il chiamante dal dover rispettare uno schema preconfigurato. In pratica, chiunque disponga di URL (Uniform Resource Locator) e API Key può scegliere liberamente il formato del payload, entro le opzioni supportate.
Il parser viene scelto automaticamente in base al MIME type dichiarato nell’header `Content-Type`:
- JSON →
`application/json` - XML →
`application/xml,text/xml` - Form →
`application/x-www-form-urlencoded,multipart/form-data`
Invio in formato JSON
Nel caso in cui sia indicato il parametro x-fl-selector viene utilizzato il sotto oggetto puntato Selettore opzionale x-fl-selector
Se è presente il query parameter HTTP x-fl-selector, l’endpoint applica l’espressione JSONPath indicata per individuare il sotto-oggetto (o l’elenco) da processare.
Se l’header non è presente, viene utilizzato l’oggetto alla root del body JSON.L’endpoint identifica automaticamente se il payload rappresenta un singolo messaggio (oggetto) oppure un insieme di messaggi (array). Le espressioni JSONPath possono selezionare elementi annidati e liste.
Esempi (JSON)
| # | Input (schematico) | Content-Type | x-fl-selector | Interpretazione |
|---|---|---|---|---|
| 1 | `[{}, {}, {}]` | application/json | (omesso) | L’intero array è un batch: 3 messaggi. |
| 2 | `{ "data": [ {}, {}, {} ] }` | application/json | data | Seleziona data: batch di 3 messaggi. |
| 3 | `[ { "children": [ {}, {}, {} ] }, { "children": [ {}, {}, {} ] }, { "children": [ {}, {}, {} ] } ]` | application/json | $.*.children[*] | Seleziona e appiattisce tutti i children: 9 messaggi. |
Nota: gli esempi sono volutamente compatti e privi di campi applicativi; in produzione i singoli {} rappresentano record/oggetti completi.
Se il parsing del payload fallisce, Flowlyze crea comunque un messaggio di fallback che contiene un campo content con il contenuto originale ricevuto. Questo garantisce tracciabilità e possibilità di ritentare l’elaborazione a valle.
Invio batchId
L’endpoint consente l’invio di un Batch ID per richiesta. I parametri possono essere forniti tramite header oppure tramite query string.
Parametri supportati
| Nome parametro | Tipo | Obbligatorio | Descrizione |
|---|---|---|---|
batchId | string | Sì | Identificativo univoco del batch (ObjectId). È consentito un solo valore per richiesta. |
processableBatch | boolean | No | Indica se il batch deve essere processato. |
Regole di elaborazione
- Se
processableBatch = true→ lo stato del batch viene impostato aPROCESSING - Se
processableBatch = falseo non fornito → lo stato del batch viene impostato aDATA_LOADING
Endpoint V1
L’endpoint V1, in fase di dismissione, si basa su una struttura dati definita a priori. Ciò significa che il flusso deve essere configurato anticipatamente per interpretare correttamente il payload in ingresso.
All’interno del flusso è necessario specificare:
L’endpoint V1 è deprecato e in dismissione. Si consiglia la migrazione verso V2 per flessibilità e robustezza.
- Consider as single object: se l’endpoint riceve un singolo oggetto
- path: percorso univoco della url (ultima parte del percorso
https://in.flowlyze.io/api/wh/{tenant_id}/{path}) - apikey: chiave univoca da passare in query string oppure in header sotto con nome di parametro x-api-key
Esempio: https://in.flowlyze.io/api/wh/flowlyze-demo/test for tenant flowlyze-demo and path test.
Parametri richiesti nel flusso
Consider as single object
Indica se l’endpoint riceve un singolo oggetto JSON per richiesta (true) oppure un insieme di oggetti (array).
- true → il payload è un singolo record.
- false → il payload è una lista di record.
Path
Percorso univoco in coda alla URL che identifica l’istanza del webhook all’interno del tenant.
Esempio: in /flowlyze-demo/test, il path è test.
API Key
Chiave univoca da fornire per l’autenticazione:
- In query string:
?x-api-key=<CHIAVE> - Oppure via HTTP header:
x-api-key: <CHIAVE>
Esempio di URL
Per il tenant flowlyze-demo e path test: https://in.flowlyze.io/api/wh/flowlyze-demo/test
Autenticazione con query string: https://in.flowlyze.io/api/wh/flowlyze-demo/prova?x-api-key=<CHIAVE>
Autenticazione con HTTP header (consigliato), esempio curl:
curl -X POST \
https://in.flowlyze.io/api/wh/flowlyze-demo/prova \
-H "x-api-key: <CHIAVE>" \
-H "Content-Type: application/json" \
-d '{ "example": "value" }'
Stato di vita e migrazione
L’endpoint V1 è in dismissione. Per una maggiore flessibilità di schema (selettori, formati, autodiscovery del batch), si raccomanda la migrazione a Endpoint V2, che permette la definizione del modello dati lato client e supporta selezione tramite JSONPath.
Http
Una Source di tipo HTTP in Flowlyze è progettata per leggere e acquisire dati da endpoint remoti accessibili via protocollo HTTP o HTTPS, tipicamente esposti da servizi web, API REST o microservizi.
I dati ricevuti vengono elaborati in formato JSON, che rappresenta il formato standard per l’interscambio strutturato di informazioni tra sistemi.
Le configurazioni avanzate disponibili nella Source HTTP permettono di gestire in modo flessibile ed efficiente diversi aspetti dell’integrazione.
Lettura incrementale (Delta Reading)
La sorgente HTTP può essere configurata per effettuare letture incrementali, ossia per acquisire solo i dati nuovi o modificati rispetto all’ultima esecuzione.
Questo meccanismo sfrutta il sistema di memoria interno di Flowlyze e consente di ottimizzare le prestazioni riducendo il volume dei dati trasferiti.
Parsing del Payload
Flowlyze consente di definire regole di parsing e trasformazione del payload JSON in ingresso, utilizzando espressioni JSONPath per identificare campi specifici, estrarre porzioni di dati o strutturare il messaggio in modo coerente con il flusso di destinazione.
Modalità di autenticazione supportate
OAuth2 (Bearer Token)
Cosa fa: ottiene un access token da un Authorization Server e lo invia all’API come Authorization: Bearer <token>.
Quando usarla: API enterprise e pubbliche moderne (OpenAPI), sicurezza elevata, scadenza/rotazione token, gestione di scope/permessi.
Configurazione tipica in Flowlyze
- Grant type: di solito Client Credentials per integrazioni server-to-server (opz. Authorization Code se c’è un utente interattivo).
- Token URL: endpoint OAuth2 (es.
https://auth.example.com/oauth/token) - Client ID / Client Secret
- Scope (opzionale)
- Header in uscita:
Authorization: Bearer {{access_token}}(inserito automaticamente una volta ottenuto il token)
Custom JWT Bearer
Cosa fa: costruisce un JWT firmato (tipicamente RS256) con claims concordati e lo invia direttamente come Bearer oppure lo scambia con un access token su un endpoint custom.
Quando usarla: API proprietarie che richiedono un JWT firmato invece del classico token OAuth, o un flusso “JWT → access token” personalizzato.
Configurazione tipica in Flowlyze
-
Algoritmo: RS256/ES256/HS256 (di norma RS256)
-
Chiave privata / Key ID (kid)
-
Claims:
iss,sub,aud,iat,exp, eventualicustom-claims -
Emissione token:
- Direct Bearer: invia il JWT come
Authorization: Bearer <jwt> - Exchange: invia il JWT a un endpoint per ottenere un access token e poi lo usa come Bearer
- Direct Bearer: invia il JWT come
Esempio header finale (direct bearer)
Authorization: Bearer eyJhbGciOiJSUzI1NiIsInR5cCI6IkpXVCJ9...
Basic Auth
Cosa fa: invia username:password codificati Base64 nell’header Authorization.
Quando usarla: servizi legacy o interni dove l’API espone Basic Auth su HTTPS.
Configurazione tipica in Flowlyze
- Username
- Password
- Header in uscita (automatico):
Nota: usare sempre HTTPS perché altrimenti le credenziali esposte via basic auth sono in chiaro.
API Key
Cosa fa: invia una chiave statica come header o query string.
Quando usarla: servizi semplici o pubblici, dove non è richiesto OAuth.
Configurazione tipica in Flowlyze
- Valore della chiave
- Posizione:
Header(es.x-api-key: <key>) oppureQuery(es.?apikey=<key>)
Esempio completo
https://api.example.com/data?filter=update_date>{{last_update}}
Il placeholder {last_update} è valorizzato da Flowlyze con l’ultimo valore incrementale memorizzato (es. massimo update_date visto).
Se l’oggetto di ritorno delle API è nella forma:
{
"data": [{}, {}, {}]
}
usa “data” come selettore per i record da ingerire.
GraphQL
Una Source di tipo GraphQL in Flowlyze è un job di ingresso schedulato che, in base alla pianificazione del flusso (es. cron), chiama un endpoint GraphQL, invia la richiesta (query o mutation) e mette in coda il payload di risposta per l'elaborazione. Estende il comportamento delle sorgenti HTTP e utilizza le impostazioni GraphQL del flusso per costruire la richiesta, inviarla e interpretare la risposta.
Consente di eseguire operazioni GraphQL verso endpoint accessibili via HTTP: il client specifica i dati desiderati e il server risponde con una struttura JSON che rispecchia la richiesta. Il trasporto tipico è HTTP (di solito POST) con body JSON.
Configurazione
| Proprietà | Descrizione |
|---|---|
| Url | URL completo dell'endpoint GraphQL (es. https://api.example.com/graphql). Non può essere vuoto. |
| Method | Metodo HTTP: GET o POST. |
| Query | Stringa della query (o mutation) GraphQL. Non può essere vuota. |
| Variables | Stringa JSON per le variabili della query. |
| OperationName | Nome dell'operazione quando il documento contiene più operazioni. |
| Headers | Header HTTP aggiunti alla richiesta (es. Authorization, X-Custom-Header). |
| HttpRequestAuthSettings | Configurazione auth (es. bearer token, API key). |
| DataField | JSON path per il campo "data" nella risposta GraphQL (JSONPath). Usato per estrarre il payload da mettere in coda. |
| ErrorsField | JSON path per l'array "errors" nella risposta. Se presente e non vuoto, il job solleva un'eccezione con i messaggi di errore. |
Gestione della risposta
La risposta di un endpoint GraphQL è in genere in formato JSON.
- Errori HTTP: se lo status HTTP non è 2xx (es. 400, 401, 403, 429, 500), la richiesta è considerata fallita e viene sollevata un'eccezione (status, body e messaggio di errore).
- Errori GraphQL: il job legge il token indicato da ErrorsField (default
"errors"). Se è un array non vuoto, raccoglie il messaggio di ogni elemento e solleva:"Error in GraphQL: {messages}". - Extensions: se la root ha un token
extensions, viene registrato a livello informativo (es. rate limit, costi query). - Estrazione dati: il token indicato da DataField (default
"data") viene usato per costruire l'elenco di messaggi:- Array: ogni elemento (come JObject) viene messo in coda come un messaggio.
- Oggetto: un solo JObject messo in coda come un messaggio.
Autenticazione
L'autenticazione è gestita come per la Source HTTP: Bearer token, API key, Basic Auth, OAuth2, JWT, ecc. (vedi sezione Http per le modalità supportate).
RDMBS
La Source di tipo RDBMS (SQL) in Flowlyze consente di connettersi ai principali database relazionali per estrarre dati tramite una query SQL personalizzabile.
Il connettore è ideale per scenari in cui i dati risiedono in database aziendali e devono essere letti in modo incrementale, parametrico o transazionale.
La query eseguita può essere:
- una semplice SELECT, anche con join e condizioni parametriche;
- oppure una stored procedure complessa che gestisce logiche di business lato database.
All’interno della query è possibile utilizzare variabili globali o parametri incrementali, risolti dinamicamente da Flowlyze (es. {{last_update}}), così da costruire query intelligenti e riutilizzabili.
Connessione
Per stabilire la connessione, è necessario configurare i parametri di accesso principali. Tutti i campi di connessione possono contenere variabili globali o secrets, per garantire sicurezza e flessibilità.
| Campo | Descrizione |
|---|---|
| DB Engine | Specifica il tipo di database relazionale da utilizzare. Flowlyze supporta i principali motori, tra cui MySQL, PostgreSQL, Oracle e Microsoft SQL Server (MSSQL). Il driver e il dialetto SQL vengono adattati automaticamente al motore selezionato. |
| Host | Indirizzo del server database. Può essere un hostname (es. db.example.com) o un indirizzo IP (es. 10.0.0.12). |
| Port | Porta di connessione del database (valori tipici: 3306 per MySQL, 5432 per PostgreSQL, 1433 per MSSQL, 1521 per Oracle). |
| Database | Nome del database (schema) a cui connettersi. Flowlyze utilizza questo valore per eseguire la query nel contesto corretto. |
| Username | Utente con privilegi di lettura (e, se richiesto, di esecuzione stored procedure) sul database. |
| Password | Credenziali di accesso associate all’utente. Si raccomanda di gestire questo valore tramite un secret per motivi di sicurezza. |
Query per selezione dati
La query principale può essere qualsiasi istruzione supportata dal database, scritta nel dialetto SQL specifico del motore scelto.
Flowlyze invia la query in modalità read-only o call procedure, in base alla sintassi utilizzata.
È possibile utilizzare:
- variabili globali (
{{variabile}}) - campi incrementali (es.
{{last_update}}) - limitazioni o paginazioni per ottimizzare la lettura dei dati
Esempi
-- 1. Importa tutti gli ordini
SELECT * FROM orders;
-- 2. Legge solo gli ordini aggiornati dopo l’ultimo valore incrementale
SELECT *`
FROM orders`
JOIN customers ON orders.customer_id = customers.id
WHERE order_update > {{last_update}}
LIMIT 1000;`
-- 3. Esegue una stored procedure che restituisce e marca i dati come “letti”
SELECT * FROM getOrdersAndAcknowledge();
💡 Le variabili (come {{last_update}}) vengono risolte in fase di esecuzione dal motore di Flowlyze, consentendo di implementare logiche di lettura incrementale o contestuale.
Query per l’Aknowdlege (TBD)
Flowlyze supporta inoltre la configurazione di una query di acknowledge, eseguita solo dopo che i dati letti sono stati correttamente ricevuti e confermati all’interno della piattaforma.
Questa query riceve come parametro il set di dati elaborati (fetchedData) e può essere utilizzata per:
- aggiornare flag di stato sui record letti (es.
processed = true), - registrare log di sincronizzazione,
- o eseguire procedure di conferma personalizzate.
Esempio di uso:
{{#set "ids"}}{{#each fetchedData}}{{this.id}}{{#unless @last}},{{/unless}}{{/each}}{{/set}}
UPDATE orders
SET processed = TRUE
WHERE id IN ({{ids}});
-- ovvero Update …. WHERE id in (1,2,3,4)
Questo meccanismo garantisce che i record vengano marcati come “letti” solo dopo l’elaborazione completa del flusso Flowlyze, evitando perdita o duplicazione di dati.
Flat File
La Source di tipo Flat File in Flowlyze consente di leggere e interpretare file strutturati in diversi formati (CSV, posizionale, XML, JSON) provenienti da una varietà di canali di acquisizione (FTP, HTTP, S3, Azure Blob Storage).
Ogni riga o unità logica del file viene trasformata in un messaggio indipendente e processata dalla piattaforma in modo asincrono, consentendo la massima scalabilità e flessibilità nei flussi di integrazione.
Canali di acquisizione
Flowlyze supporta diversi canali di acquisizione per recuperare i file sorgente:
| Canale | Descrizione |
|---|---|
| FTP / FTPS / SFTP | Connessione diretta a un server FTP per scaricare file in modo sicuro. È possibile autenticarsi tramite utente/password o chiave SSH e specificare percorsi di cartelle, pattern di file o regole di retention. |
| HTTP (TBD) | Download di un file remoto esposto via HTTP o HTTPS, con possibilità di autenticazione (API key, Basic Auth o Bearer token). |
| Amazon S3 (TBD) | Connessione a un bucket S3 per scaricare file JSON, CSV o XML. È possibile filtrare per prefisso o nome file. |
| Azure Blob Storage (TBD) | Accesso a un contenitore (container) Blob in Azure per il download e la lettura del file. Supporta autenticazione tramite connection string o service principal. |
| Azure Blob Storage RFE | Variante del connettore Azure Blob con funzionalità estese per flussi di elaborazione multipli o coordinati. (In sviluppo) |
Protocolli di lettura
Flowlyze supporta due modalità di accesso e gestione dei file, dette protocolli di lettura:
Coordinato
In questa modalità, Flowlyze opera su una cartella di lavoro a cui ha permessi di lettura e scrittura.
Il processo prevede:
- Copia del file dalla cartella sorgente in una cartella temporanea di elaborazione.
- Lettura e parsing dei contenuti.
- Spostamento del file in una cartella di completamento al termine dell’elaborazione.
Vantaggi:
- Visibilità sui file non ancora processati
- Possibilità di analizzare eventuali errori
- Tracciabilità completa del ciclo di vita dei file
La pulizia periodica delle cartelle e la gestione degli artefatti è a carico dell’utilizzatore.
Semplice (TBD)
Flowlyze scarica e processa direttamente il file dalla sorgente, senza generare copie locali.
In caso di errore, la piattaforma genera un messaggio di errore nel flusso con il dettaglio della causa, ma non conserva una copia del file originale.
Formati supportati
La Source Flat File è in grado di interpretare vari formati di dati strutturati:
| Formato | Stato | Descrizione |
|---|---|---|
| CSV | Implementato | File a valori separati da delimitatore, con opzioni di parsing avanzato (header, quote, cultura, delimitatori personalizzati). |
| JSON | Implementato | Parsing di file JSON complessi con supporto a JSONPath per selezionare le entità da elaborare. |
| Posizionale | TBD | File a larghezza fissa, con definizione esplicita della posizione di ogni campo. |
| XML | TBD | Lettura di file XML con selettori XPath e mapping automatico dei nodi. |
Configurazione CSV
Per il formato CSV, Flowlyze consente una configurazione dettagliata dei parametri di parsing:
| Parametro | Descrizione |
|---|---|
| Line Delimiter | Delimitatore di riga, di norma \n o \r\n. |
| Column Delimiter | Separatore tra colonne (default ,). Può essere modificato in ;, ` |
| Quote Character | Carattere di quotazione usato per i campi contenenti delimitatori o spazi (default "). |
| Culture | Imposta la cultura usata per interpretare numeri e date (es. it-IT, en-US). |
| Has Header | Indica se la prima riga del file contiene i nomi delle colonne (true/false). |
| Grouping Column | Specifica una colonna da utilizzare per raggruppare più righe in un unico messaggio. |
Funzionalità di Raggruppamento delle Righe
Flowlyze consente di raggruppare più righe di un file sorgente in un unico messaggio logico, utilizzando una colonna di raggruppamento.
Questo meccanismo è utile quando il file contiene dati che rappresentano relazioni gerarchiche o versioni multiple dello stesso record, e si desidera trattarli come un’unica entità nella pipeline.
Durante il parsing, Flowlyze analizza il valore della colonna di raggruppamento (ad esempio product_id, record_id, ecc.).
Tutte le righe che condividono lo stesso valore vengono aggregate in un unico oggetto JSON.
Ogni gruppo genera un singolo messaggio in uscita, contenente i dati comuni e l’elenco delle righe raggruppate in un array secondario.
Esempio 1 – Raggruppamento varianti per prodotto principale
Scenario: un file CSV contiene le varianti di prodotto (taglia, colore, prezzo) associate a un prodotto principale identificato da product_id.
File di origine
| product_id | variant_id | color | size | price |
|---|---|---|---|---|
| 1001 | 1 | red | M | 29.90 |
| 1001 | 2 | blue | L | 31.50 |
| 1002 | 3 | black | S | 28.00 |
Colonna di raggruppamento: product_id
Output aggregato
{
"product_id": 1001,
"variants": [
{ "variant_id": 1, "color": "red", "size": "M", "price": 29.90 },
{ "variant_id": 2, "color": "blue", "size": "L", "price": 31.50 }
]
},
{
"product_id": 1002,
"variants": [
{ "variant_id": 3, "color": "black", "size": "S", "price": 28.00 }
]
}
In questo caso, Flowlyze costruisce un messaggio per ogni prodotto principale, includendo tutte le varianti come array all’interno del campo variants.
Anche se la colonna di raggruppamento è una sola (product_id), il risultato è un oggetto gerarchico utile per successive fasi di mapping o invio a un sistema target (ad esempio un ERP o un sistema e-commerce).
Esempio 2 – Raggruppamento di salvataggi multipli (tabelle di journaling)
Scenario: un sistema sorgente registra più versioni o aggiornamenti dello stesso record in una tabella di journaling o audit.
Ogni riga rappresenta un salvataggio, ma nel flusso di integrazione può essere utile consolidare tutte le versioni in un unico messaggio logico.
File di origine
| record_id | update_time | field | old_value | new_value |
|---|---|---|---|---|
| 501 | 2025-10-01 10:30:00 | status | draft | pending |
| 501 | 2025-10-02 11:45:00 | status | pending | approved |
| 501 | 2025-10-03 09:20:00 | note | null | "OK" |
Colonna di raggruppamento: record_id
Output aggregato
{
"record_id": 501,
"data": [
{
"update_time": "2025-10-01T10:30:00Z",
"field": "status",
"old_value": "draft",
"new_value": "pending"
},
{
"update_time": "2025-10-02T11:45:00Z",
"field": "status",
"old_value": "pending",
"new_value": "approved"
},
{
"update_time": "2025-10-03T09:20:00Z",
"field": "note",
"old_value": null,
"new_value": "OK"
}
]
}
In questo esempio, Flowlyze genera un solo messaggio per ciascun record_id, contenente la storia completa delle modifiche in ordine cronologico. Questo consente di consolidare più versioni in un’unica rappresentazione coerente e pronta per l’invio verso sistemi di destinazione (ad esempio un data lake, un CRM o un servizio di auditing).
Configurazione JSON
Per il formato JSON, Flowlyze supporta la lettura di file JSON strutturati, semplici o complessi, con la possibilità di selezionare una porzione specifica del documento tramite JSONPath.
La configurazione JSON è volutamente minimale: il comportamento di parsing dipende principalmente dalla struttura del nodo selezionato (oggetto, array o valore singolo).
Parametri di configurazione
| Parametro | Descrizione |
|---|---|
| Json Path | Espressione JSONPath che identifica il nodo del documento JSON da cui leggere i dati. Se non specificata, vuota o impostata a "$", viene utilizzata la radice del documento. |
Comportamento di parsing
Una volta determinato il nodo di destinazione (radice o nodo selezionato tramite JSONPath), Flowlyze genera uno o più messaggi in base al tipo del nodo:
| Tipo di nodo | Risultato |
|---|---|
| Oggetto JSON | Viene generato un singolo messaggio contenente l’intero oggetto. |
| Array JSON | Viene generato un messaggio per ogni elemento dell’array. |
| Valore singolo (stringa, numero, booleano, ecc.) | Viene generato un singolo messaggio contenente il valore. |
Questo comportamento è identico sia quando si utilizza la radice del documento sia quando si usa un JSONPath.
Utilizzo senza Json Path
Se Json Path non è configurato oppure è impostato a "$":
- L’intero file JSON viene letto.
- La radice del documento viene usata come nodo di input.
- La generazione dei messaggi dipende dal tipo della radice:
- Oggetto → 1 messaggio
- Array → N messaggi (uno per elemento)
Utilizzo con Json Path
Quando Json Path è valorizzato:
- Il file viene analizzato come JSON.
- L’espressione JSONPath viene applicata per individuare un nodo specifico (ad esempio un array o un oggetto annidato).
- Se il percorso non corrisponde ad alcun nodo, viene generato un errore di configurazione.
- Il nodo individuato diventa l’input per la generazione dei messaggi, seguendo le stesse regole viste sopra.
Esempi di configurazione
Oggetto JSON come radice
{ "id": 1, "name": "Example" }
Configurazione:
- Json Path: (non impostato)
Risultato:
- Viene generato un singolo messaggio contenente l’oggetto JSON completo.
Array JSON come input
[
{ "id": 1 },
{ "id": 2 }
]
Configurazione:
- Json Path: (non impostato)
Risultato:
- Vengono generati due messaggi, uno per ciascun elemento dell’array.
Selezione tramite Json Path
{
"data": {
"items": [
{ "id": 1 },
{ "id": 2 }
]
}
}
Configurazione:
- Json Path:
$.data.items
Risultato:
- Vengono generati due messaggi, uno per ciascun elemento dell’array
items.
Json Path non valido
Configurazione:
- Json Path:
$.missing.path
Risultato:
- Errore di configurazione: il percorso JSONPath non individua alcun nodo nel documento.